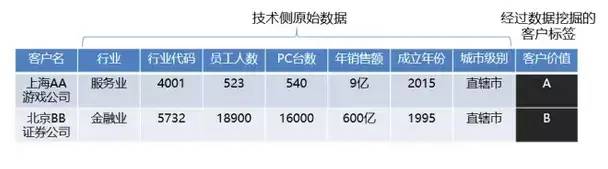

用户画像,英文为Customer Profiling或Persona,中心在于标签化,意图在于得出结论,事务决议计划。
一、实践经历
管理层想要用户画像,个人感觉主要有两方面的事务原因:
1、风控,特别是依据前史数据中,带来最大盈余的用户,放款后开展越来越好的用户的特色,进行数据发掘。
2、产品规划,怎么愈加场景化,添加产品的吸引力。
其他比方回绝回捞、精准营销等都是随手的作业了。
逼格很高,数据丰厚,领导宏图大志,期望画像越丰厚、越详尽越好。工程浩大,但实践事务人员却觉得没啥用,无法直接支撑运营,又看得人头晕目眩,沦为数据的简略提取和核算加工。这儿总结一下失利的原因,也算没有白干。
1、回头来看,至少应领先做一些简略的、有必要的数据项,依据事务的需求再逐渐添加,节约物力人力,关于添加内容也有的放矢(很或许是来自事务的实践需求)。
主张前期包含的数据:人口根本特点、前史信誉特点,我司前史请求还款记载,要以强相关信息、定性数据(标签化、抽象化)为主。方针是帮忙事务挑选出感爱好的客户,定量数据不利于事务直接适用,也由此看出穆迪这类公司为什么会输出企业评级而不是企业信誉分。
2、问题界说与问题不行解。
首要,应当详细的场景详细去挑选适宜的用户标签,不存在一个通用的用户画像。先有事务场景,再有字段需求,如运用银联数据+自身数据+信誉卡数据,发现信誉卡消费超越其月收入的用户,引荐其进行消费分期。
其次,如放款后的客户,屡次续贷而且企业开展越来越好,个人认为是比较难经过内部的一些数据描绘出来的,自身便是一个无法转换为数据问题的事务问题,不行解。
最终,咱们的用户标签是很浅显的、稀少的,最大的价值便是便利一点、会集一点,想要对事务有更大的价值,应当提取的是隐形的标签(事务无法直接获取的),比方用户的告贷意图、用户资金偏好(适用于授信后客户回绝承受场景)、产品的运用频次等,当然这需求运用一些模型(简略的规矩模型也行)和算法得到。
二、事例研讨
1、电商事例
用户样本挑选,意图是区隔用户,能够将杂乱的后台数据(事务不行得或需耗费许多精力取得)转换为简略、可了解的事务标签(用户描绘)。
用户画像的数据模型,能够归纳为下面的公式:用户标识+ 时刻 + 行为类型 +接触点(网址+内容),某用户因为在什么时刻、地址、做了什么事,打上XX标签(如母婴、红酒等)。
用户标签的权重或许随时刻的添加而衰减,界说时刻为衰减因子r,行为类型、网址决议了权重,内容决议了标签,进一步转换为公式:标签权重=衰减因子×行为权重×网址子权重。
2、标签系统事例
构建标签系统
干流的标签系统都是层次化的,首要标签分为几个大类,每个大类下进行逐层细分。
依据原始数据首要构建的是现实标签,现实标签能够从数据库直接获取(如注册信息),或经过简略的核算得到。这类标签构建难度低、实践含义清晰,且部分标签可用作后续标签发掘的根底特征(如产品购买次数可用来作为用户购物偏好的输入特征数据)。
模型标签是标签系统的中心,也是用户画像作业量最大的部分,大多数用户标签的中心都是模型标签,需求用到机器学习和自然语言处理技能。
最终结构的是高档标签,高档标签是依据现实标签和模型标签进行核算建模得出的,它的结构多与实践的事务目标紧密联系。只要完结根底标签的构建,才干够结构高档标签。构建高档标签运用的模型,能够是简略的数据核算,也能够是杂乱的机器学习模型。
详细标签构建
以三类标签为例,三类标签的特性、运用的技能均存在差异。人口特点标签,比较稳定,一旦树立很长一段时刻根本不必更新,标签系统也比较固定;爱好特点标签,随时刻改变很快,有很强的时效性,标签系统也不固定;地舆特点标签,时效性跨度很大,如GPS轨道标签需求做到实时更新,而常住地标签一般能够几个月不必更新。
许多产品(如QQ、facebook等)会引导用户填写根本信息,包含年纪、性别、收入等人口特点,但完好填写个人信息的用户只占很少一部分。一般会用填写了信息的这部分用户作为样本,把用户的行为数据作为特征练习模型,对无标签的用户进行人口特点的猜测。这种模型把用户的标签传给和他行为类似的用户,能够认为是对人群进行了标签分散,因而常被称为标签分散模型。
经过剖析,咱们发现男性和女人,关于影片的偏好是有不同的,因而运用观看的影片列表来猜测用户性别有必定的可行性。此外咱们还能够考虑用户的观看时刻、浏览器、观看时长等,为了简化,这儿只运用用户观看的影片特征。关于猜测性别这样的二分类模型,假如行为的区分度较好,一般精确率和掩盖率都能够到达70%左右。
爱好画像是互联网范畴运用最广泛的画像,主要是从用户海量行为日志中进行中心信息的抽取、标签化和核算,因而在构建用户爱好画像之前,需求先对用户有行为的内容进行内容建模。内容建模需求留意粒度,过细的粒度会导致标签没有泛化才干和运用价值,过粗的粒度会导致没有区分度。
新闻数据自身对错结构化的,运用文本主题聚类完结主题标签的构建,形成对新闻内容从粗到细的“分类-主题-关键词”三层标签系统内容建模(如LDA之类的)。在完结内容建模今后,咱们就能够依据用户点击,核算用户对分类、主题、关键词的爱好,得到用户爱好标签的权重。
用户对每个词的爱好核算公式:,表明词在这篇新闻中的权重。该公式有两个问题:一个是用户的爱好累加是线性的,数值会十分大,老的爱好权重会特别高;一个是用户的爱好有很强的时效性,昨日的点击要比一个月之前的点击重要的多,线性叠加无法杰出近期爱好。
咱们运用如下的办法对爱好得分进行次数衰减和时刻衰减。次数衰减的公式:,时刻衰减的公式:,依据用户爱好改变的速度、用户活跃度等要素,也能够对爱好进行周等级、月等级或小时等级的衰减。
地舆位置画像常驻地的发掘,依据用户IP地址的解析,对用户IP呈现的城市进行核算就能够得到常驻城市标签,不只能够用来核算各个地域的用户散布,还能够依据用户在各个城市之间的出行轨道辨认出差人群、旅行人群等。GPS数据一般从手机端搜集,但许多手机APP没有获取用户 GPS信息的权限。
用户画像作用评价
爱好画像的人为评价比较困难,常用评价办法是规划小流量的A/B-test进行验证,能够挑选一部分标签用户,给这部分用户进行和标签相关的推送,看标签用户对相关内容是否有更好的反应,例如假如这批用户的点击率和阅览时长显着高于平均水平,就阐明标签是有用的。
用户画像的评价目标主要是指精确率、掩盖率、时效性目标。标签还需求有必定的可解释性(便于了解)和可扩展性(便于保护,后续标签的添加)。
标签的精确率指的是被打上正确标签的用户份额,精确率是用户画像最中心的目标,一个精确率十分低的标签是没有运用价值的。评价一般有两种办法:一种是在标示数据集里留一部分测试数据;另一种是在全量用户中抽一批用户,人工标示评价精确率。因为初始的标示数据集的散布和全量用户散布比较或许有必定误差,故后一种办法的数据更可信。精确率一般是对每个标签别离评价,多个标签放在一同评价精确率是没有含义的。
标签的掩盖率指的是被打上标签的用户占全量用户的份额,与精确率是一对对立的目标,能够拆解为两个目标来评价,标签掩盖的用户份额(掩盖的广度)、掩盖用户的人均标签数(掩盖的密度)。掩盖率既能够对单一标签核算,也能够对某一类标签核算,还能够对全量标签核算,均有含义。
用户掩盖份额:。人均标签数:
时效性,如爱好标签、呈现轨道标签等,一周之前的就没有含义了,如性别、年纪等,能够有一年到几年的有用期。关于不同的标签,需求树立合理的更新机制,以确保标签时刻上的有用性。
用户画像的运用
一般需求一个可视化途径,对标签进行检查和检索。此外,咱们还能够运用不同维度的标签,进行高档的组合剖析,产出高质量的剖析陈述。
3、用户实时风格偏好建模
建模标签清晰,用户偏好的产品风格,建模流程如下图:
标签产出的建模流程如下图,运用依据user-产品原始核算为根底的topic model解决方案(PLSA、LDA、人工review topic下的词)。
在此根底上,添加性别、年纪段、购买力(保藏、购买、点击产品的简略核算+协同过滤)等猜测类标签,添加维度进行愈加精确的个性化引荐。
本事例作者也进行了新品投进方面的运用,值得学习,我的了解其实就正反两面,好的客户找到对应的特别标签,剖析来历途径、广告呼应等,有了数据再进一步迭代进步猜测精确度;坏的客户就堵截途径,做规矩拒单。
4、消金逾期客户画像
根本相当于数据剖析,从不同维度去调查客户的占比、逾期率、首逾率、不良率。
以征信认证逾期为例,能够看到散布及逾期状况是否与事务预期共同,如存在差异则需及时调整贷前风控战略。本途径告贷额度低、期限短,一般人不会为了这种告贷去打印人行征信,假如供给了人行征信,客户多头假贷、中介包装危险较高,主张侧重审阅,数据体现也与事务了解共同。
5、客户画像中常用的AI算法
主要是NLP,分词、实体辨认和词性标示同属序列标示问题,是根底作业。主题模型(Topic Model,LDA等,替代传统的聚类办法)、TF-IDF、Word2Vec(Embedding办法,可为每个词学习到一个稠密向量)等,得到了如标签(关键词、分类)、主题、嵌入向量(都能够了解为特征)。假如把用户对物品的行为,消费或许没有消费看成是一个分类问题,用户用实践行动帮咱们标示了若干数据,那么挑选出他实践感爱好的特性便是特征挑选的问题。
TF-IDF ,词频(Term Frequency),逆文本频率指数(Inverse Document Frequency),TF表述的中心思维是,在1条文本中重复呈现的词更重要。而IDF的思维是,在所有文本都呈现的词是不重要的,IDF用于批改TF所表明的核算结果。
TF-IDF用于出产用户的偏好标签,可核算得到某个词语(标签)对用户的权重,并找到类似的用户。一起可进一步引进行为类型(订单未付出、已付出未退款、已付出已退款等状况)、行为次数和时刻衰减(牛顿冷却规律)的权重,调整标签权重。
三、经历与主张
想清楚客户画像的运用场景(做好顶层规划,才干有用操控投入资源,否则是无底洞)、支撑客户画像的数据源(数据的可得性、数据的标准化、数据核算口径的一致等)、作用评价与事务运用价值的闭环。
附,参考资料:
1、【干货】依据常识图谱的用户了解,https://zhuanlan.zhihu.com/p/54834467
2、[干货]怎么构建用户画像,http://www.woshipm.com/pmd/107919.html
3、干货请收好:总算有人把用户画像的流程、办法讲理解了,https://zhuanlan.zhihu.com/p/52756026
4、Spark机器学习进阶实战,马海平著。
5、用户画像-实战事例,https://zhuanlan.zhihu.com/p/36395328
6、构建用户画像中所用到的AI算法,https://mp.weixin.qq.com/s/2cxhcz9k6N3cTslVRScVlA
7、网贷用户画像及不良率剖析,https://zhuanlan.zhihu.com/p/153338705
作者:草木芃
链接:https://www.jianshu.com/p/fe16a5d744d6
上一年今天运营文章2022:网站百度核算中呈现已屏蔽,这是什么原因?(0)2022:一份思路清晰的用户生长系统规划方案(1)2022:《U型考虑》学习笔记(0)2022:小红书达人top排行榜丨2022年1月创作者榜单(0)2022:品类月销售额破10亿,2022抖音电商发力点是什么?(0)
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



{kind=link}