 1.前语
1.前语
RFM模型即”R”——Recency(最近一次消费时刻)、”F”——Frequency(一段时刻内消费频次)、”M”——(一段时刻内消费总额)。这三个目标可以将咱们的用户划分红不同的等级和层次,意图是为了衡量他们的用户价值,然后可以更准确地将本钱和精力花在更准确的用户层次身上。一个典型的比方便是针对一个显着无志愿的丢失用户,对其持续push自己的中心产品,费时吃力也费钱。
2.怎么用Python树立RFM模型
RFM模型,尽管字眼中带着“模型”二字,但实践它底子不需求任何的算法支撑,和数据建模中的逻辑回归,聚类剖析等是彻底不同的概念。因而完成RFM的东西和办法有许多:SQL, Excel, R等等都可以做到,当然Python也不破例,RFM模型的中心便是将三个目标进行标签化,然后依据实践场景事务需求进行分层即可。下面的文章我就经过一个简略的比方来经过代码完成RFM模型的树立。
2.1数据导入
链接:https://pan.baidu.com/s/1YbZrdsg2dOoe_5lylTwhQw 提取码:nf2f 数据是某电商的一款SKU于2018年的出售表单,字段自身只要4个,可是满足树立RFM模型了。
import os import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.serif'] = ['SimHei'] plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus']=False sns.set_style('ticks', {'font.sans-serif':['simhei','Droid Sans Fallback']}) 2.2 数据清洗
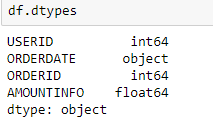
df = pd.read_csv('sale.csv') df.drop_duplicates(subset=['ORDERID'],keep='first',inplace=True) df.dtypes dtypes.png
可以看到咱们各个字段的数据类型,注意到其间的ORDERDATE是字符串类型,而不是时刻Datetime类型,这个需求在后面进行转化。其它字段都正常。
df[df.isna().values == True] df = df.dropna(how='any', axis=0) 检查空值.png
可以看到上面有些数据出现了空值,由于空值无法核算出RFM,所以直接删去。
plt.figure(figsize=(10,5)) sns.distplot(df.AMOUNTINFO) 数据全体散布.png
经过直方图咱们可以很明晰地看到数据的全体散布状况,出现偏态散布,不过没有负值,因而不需求处理异常值,>0的值都是合理的。
df['ORDERDATE'] = pd.to_datetime(df['ORDERDATE']) df['Datediff'] = (pd.to_datetime('today') - df['ORDERDATE']).dt.days df 增加一列R.png
数据的终究处理,便是将ORDERDATE转化成Datetime时刻类型,并增加一列时刻差,作为”R”的核算目标。
2.3数据剖析
R_Agg = df.groupby(by=['USERID'])['Datediff'] R_Agg = R_Agg.agg([('最近一次消费','min')]) F_Agg = df.groupby(by=['USERID'])['ORDERID'] F_Agg = F_Agg.agg([('2018年消费频次','count')]) M_Agg = df.groupby(by=['USERID'])['AMOUNTINFO'] M_Agg = M_Agg.agg([('2018年消费金额',sum)]) rfm = R_Agg.join(F_Agg).join(M_Agg) rfm 上面的过程是别离核算了RFM模型中的三个目标: R,F,M,将其合并成一张新表,如下图:
RFM表1.png
然后便是最要害的一步了,经过pd.cut办法,将用户分层并打上标签,这儿我用的分层办法是python中的quantile函数,由于咱们之前的直方图看到是偏态散布,所以取均值来分层的差错会很大,这时候挑选分位数来分层会更好。
def rfm_convert(x): rfm_dict = {0:'R', 2:'M'} try: for i in range(0,3,2): bins = x.iloc[:,i].quantile(q=np.linspace(0,1,num=6),interpolation='nearest') if i == 0: labels = np.arange(5,0,-1) else: labels = np.arange(1,6) x[rfm_dict[i]] = pd.cut(x.iloc[:,i],bins=bins,labels=labels,include_lowest=True) except Exception as e: print(e) rfm_convert(rfm) 上面这个函数的意图是将R和M依照1-5的等级打上标签,给用户分层,但由于F的数值大多会集在1,即消费频次只要1次,所以无法运用分位数办法来均分出5个等级,因而我下面额定再运用其它办法将其打上标签:
bins = [1,3,5,12] labels = np.arange(1,4) rfm['F'] = pd.cut(rfm['2018年消费频次'], bins=bins, labels=labels, include_lowest=True) rfm.insert(4,'F',rfm.pop('F')) rfm F的分层是由我手动区别的,由于RFM模型自身便是依据不同场景和事务需求来树立的,因而这儿的F我就依据数据的实践散布状况来手动分层了。
RFM表2.png
好,那么至此RFM模型已经有了个雏形,终究要做的,便是打上标签:
rfm_model = rfm.filter(items=['R','F','M']) def rfm(x): return x.iloc[0]*3+x.iloc[1]+x.iloc[2]*3 rfm_model['RFM'] = rfm_model.apply(rfm,axis=1) bins = rfm_model.RFM.quantile(q=np.linspace(0,1,num=9),interpolation='nearest') labels = ['丢失客户','一般保持客户','新客户','潜力客户','重要款留客户','重要深耕客户','重要唤回客户','重要价值客户'] rfm_model['Label of Customer'] = pd.cut(rfm_model.RFM, bins=bins, labels=labels, include_lowest=True) rfm_model RFM表3.png
这儿的RFM分数依据详细场景和事务来分配权重,这儿我给的权重比是3:1:3,,那么其实也可以不要这个加权分数,彻底依据独自的R,F,M来标签,比方R>=4、F>1、M>=4的,算中心用户。
4.数据可视化
以上便是RFM模型了,那么有了模型之后,咱们就能直观地看到各个层级下的用户散布以及用户价值了:
from pyecharts.charts import Grid, Pie, Bar from pyecharts import options as opts tmp = rfm_model.groupby('Label of Customer').size() t = [list(z) for z in zip(tmp.index.values, tmp.values)] # 制作饼图 pie = ( Pie() .add('',t, radius=['30%','75%'], rosetype='radius', label_opts=opts.LabelOpts(is_show=True)) .set_global_opts(title_opts=opts.TitleOpts(title='顾客分层结构',pos_left='center'), toolbox_opts=opts.ToolboxOpts(is_show=True), legend_opts=opts.LegendOpts(orient='vertical',pos_right='2%',pos_top='30%')) .set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{d}%'))) pie.render_notebook() 顾客分层结构.png
可以看到无价值的丢失客户占有了很大一部分,可是一起咱们也要关注到,新客户的占比量是相当大的,不过,单纯看占比是没有意义的,由于咱们终究的意图是盈余,因而下面咱们再结合消费金额散布状况,来看下咱们实践应该针对哪些层级的用户进行精准投进:
consumer_r = df.groupby('USERID').AMOUNTINFO.agg([('消费总额',sum)]) new_rfm = rfm_model.join(consumer_r) filter_list = ['丢失客户','新客户','重要款留客户','重要价值客户'] new_rfm = new_rfm[new_rfm['Label of Customer'].astype('<U').isin(filter_list)] new_rfm['Label of Customer'] = new_rfm['Label of Customer'].astype('<U') tmp = new_rfm.groupby('Label of Customer').消费总额.sum() tmp = tmp.sort_values() from pyecharts.charts import Bar yindex = [] for i in list(tmp.values): yindex.append(int(i)) # 制作柱状图 bar = (Bar(init_opts=opts.InitOpts(theme='white',bg_color='papayawhip')) .add_xaxis(list(tmp.index.values)) .add_yaxis('顾客分层',yindex,color='lightcoral', category_gap='70%') .set_global_opts(title_opts=opts.TitleOpts(title='不同分层顾客2018年消费总额',pos_left='center',title_textstyle_opts=opts.TextStyleOpts(color='lightcoral')), legend_opts=opts.LegendOpts(pos_top='bottom'), toolbox_opts=opts.ToolboxOpts(is_show=True), yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter='{value}'))) ) bar.render_notebook() 不同分层顾客2018年消费总额.png
结合上面的饼图,咱们可以终究得出结论,尽管新客户的人群占比是最大的,可是他们实践奉献的金额并不高,所以咱们没有必要在拉新这一块花费太多心思和精力,而应该侧重将运营的重心放在“留存”和“变现”上,怎么留住中心收入来历的“重要价值用户”以及经过用户触达的各种办法,召回“重要款留客户”,是现阶段的使命。
5.总结
经过上面的RFM模型树立和可视化,咱们其实可以发现,经过对用户的精准分层,咱们可以对用户价值有个更直观的感触,然后对互联网产品的运营,起到点对点服务的效果。
原文作者:NXLLno
上一年今天运营文章2022:《我在阿里做运营》读书笔记&思想导图(0)2022:8月营销日历参阅:4号七夕,88大促(0)2021:一文读透《考虑,快与慢》(0)2021:阿里第一代政委亲述文明落地:100次的重复便是着重,100次的着重才干成功(0)2021:抖音直播复盘总结,抖音复盘究竟都在做些什么(0)
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



{kind=link}